2025-03-30 13:46:26 +08:00
|
|
|
|
<h2><center>Shell awk</center></h2>
|
|
|
|
|
|
|
|
|
|
|
|
------
|
|
|
|
|
|
|
|
|
|
|
|
## 一:AWK
|
|
|
|
|
|
|
|
|
|
|
|
### 1. awk 介绍
|
|
|
|
|
|
|
|
|
|
|
|
`awk`是一种编程语言,用于在`linux/unix`下对文本和数据进行处理。数据可以来自标准输入、一个或多个文件,或其它命令的输出。它支持用户自定义函数和动态正则表达式等先进功能,是`linux/unix`下的一个强大编程工具。它在命令行中使用,但更多是作为脚本来使用。
|
|
|
|
|
|
|
|
|
|
|
|
`awk`的处理文本和数据的方式是这样的,它逐行扫描文件,从第一行到最后一行,寻找匹配的特定模式的行,并在这些行上进行你想要的操作。如果没有指定处理动作,则把匹配的行显示到标准输出(屏幕),如果没有指定模式,则所有被操作所指定的行都被处理。`awk`分别代表其作者姓氏的第一个字母。因为它的作者是三个人,分别是`Alfred Aho`、`Brian Kernighan`、`Peter Weinberger`。`gawk`是`awk`的`GNU`版本,它提供了`Bell`实验室和`GNU`的一些扩展。
|
|
|
|
|
|
|
|
|
|
|
|
### 2. 语法格式
|
|
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
|
awk [-F field-separator] 'commands' input-file(s)
|
|
|
|
|
|
awk [options] 'commands' var=value file(s)
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
- `commands`是真正 AWK 命令,[-F域分隔符]是可选的。 `input-file(s)`是待处理的文件。
|
|
|
|
|
|
- `awk`中,文件的每一行中,由域分隔符分开的每一项称为一个域。通常,在不指名`-F`域分隔符的情况下,默认的域分隔符是空格。
|
|
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
|
awk -f awk-script-file input-file(s)
|
|
|
|
|
|
awk [options] -f scriptfile var=value file(s)
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
- `-f`选项加载`awk-script-file`中的`awk`脚本,`input-file(s)`是待处理的文件。
|
|
|
|
|
|
- 将所有的`awk`命令插入一个脚本文件,使用`awk`命令解释器作为脚本的首行,相当于`shell`脚本首行的:`#!/bin/sh`可以换成:`#!/bin/awk`。通过执行脚本来调用。
|
|
|
|
|
|
|
|
|
|
|
|
### 3. 工作原理
|
|
|
|
|
|
|
|
|
|
|
|
`awk`工作流程可分为三个部分:
|
|
|
|
|
|
|
|
|
|
|
|
- 读输入文件之前执行的代码段(由`BEGIN`关键字标识)。
|
|
|
|
|
|
- 主循环执行输入文件的代码段。
|
|
|
|
|
|
- 读输入文件之后的代码段(由`END`关键字标识)。
|
|
|
|
|
|
|
|
|
|
|
|
**`awk`命令结构**
|
|
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
|
awk 'BEGIN{ commands } pattern{ commands } END{ commands }'
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
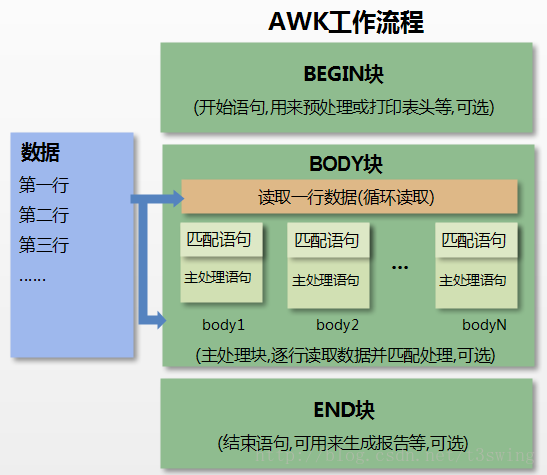
下图是`awk`的工作流程
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- 通过关键字`BEGIN`执行`BEGIN`块的内容,即 BEGIN 后花括号 **{}** 的内容。
|
|
|
|
|
|
- 完成`BEGIN`块的执行,开始执行`body`块。
|
|
|
|
|
|
- 读入有 **\n** 换行符分割的记录。
|
|
|
|
|
|
- 将记录按指定的域分隔符划分域,填充域,**$0** 则表示所有域(即一行内容),**$1** 表示第一个域,**$n** 表示第 n 个域。
|
|
|
|
|
|
- 依次执行各`BODY`块,`pattern`部分匹配该行内容成功后,才会执行`awk-commands`的内容。
|
|
|
|
|
|
- 循环读取并执行各行直到文件结束,完成`body`块执行。
|
|
|
|
|
|
- 开始`END`块执行,`END`块可以输出最终结果。
|
|
|
|
|
|
|
|
|
|
|
|
**开始块**
|
|
|
|
|
|
|
|
|
|
|
|
开始块的语法格式如下:
|
|
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
|
BEGIN {awk-commands}
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
开始块就是在程序启动的时候执行的代码部分,并且它在整个过程中只执行一次。
|
|
|
|
|
|
|
|
|
|
|
|
一般情况下,我们可以在开始块中初始化一些变量。
|
|
|
|
|
|
|
|
|
|
|
|
`BEGIN`是`AWK`的关键字,因此它必须是大写的。
|
|
|
|
|
|
|
|
|
|
|
|
**注意:**
|
|
|
|
|
|
|
|
|
|
|
|
开始块部分是可选的,你的程序可以没有开始块部分。
|
|
|
|
|
|
|
|
|
|
|
|
**主体块(BODY)**
|
|
|
|
|
|
|
|
|
|
|
|
主体部分的语法格式如下:
|
|
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
|
/pattern/ {awk-commands}
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
对于每一个输入的行都会执行一次主体部分的命令。
|
|
|
|
|
|
|
|
|
|
|
|
默认情况下,对于输入的每一行,`AWK`都会执行命令。但是,我们可以将其限定在指定的模式中。
|
|
|
|
|
|
|
|
|
|
|
|
**注意**:
|
|
|
|
|
|
|
|
|
|
|
|
在主体块部分没有关键字存在。
|
|
|
|
|
|
|
|
|
|
|
|
**结束块(END)**
|
|
|
|
|
|
|
|
|
|
|
|
结束块的语法格式如下:
|
|
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
|
END {awk-commands}
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
结束块是在程序结束时执行的代码。`END`也是`AWK`的关键字,它也必须大写。 与开始块相似,结束块也是可选的。
|
|
|
|
|
|
|
|
|
|
|
|
**示例:**
|
|
|
|
|
|
|
|
|
|
|
|
先创建一个名为 marks.txt 的文件。其中包括序列号、学生名字、课程名称与所得分数。
|
|
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
|
1) 张三 语文 80
|
|
|
|
|
|
2) 李四 数学 90
|
|
|
|
|
|
3) 王五 英语 87
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
接下来,我们将使用 AWK 脚本来显示输出文件中的内容,同时输出表头信息。
|
|
|
|
|
|
|
|
|
|
|
|
```bash
|
|
|
|
|
|
awk 'BEGIN{printf "序号\t名字\t课程\t分数\n"} {print}' marks.txt
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
执行以上命令,输出结果如下:
|
|
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
|
序号 名字 课程 分数
|
|
|
|
|
|
1) 张三 语文 80
|
|
|
|
|
|
2) 李四 数学 90
|
|
|
|
|
|
3) 王五 英语 87
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
程序开始执行时,`AWK`在开始块中输出表头信息。在主体块中,`AWK`每读入一行就将读入的内容输出至标准输出流中,一直到整个文件被全部读入为止。
|
|
|
|
|
|
|
|
|
|
|
|
### 4. awk 选项
|
|
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
|
-F fs or --field-separator fs
|
|
|
|
|
|
# 指定输入文件折分隔符,fs 是一个字符串或者是一个正则表达式,如 -F:。
|
|
|
|
|
|
|
|
|
|
|
|
-v var=value or --asign var=value
|
|
|
|
|
|
# 赋值一个用户定义变量。
|
|
|
|
|
|
|
|
|
|
|
|
-f scripfile or --file scriptfile
|
|
|
|
|
|
# 从脚本文件中读取 awk 命令。
|
|
|
|
|
|
|
|
|
|
|
|
-mf nnn and -mr nnn
|
|
|
|
|
|
# 对 nnn 值设置内在限制,-mf 选项限制分配给 nnn 的最大块数目;-mr 选项限制记录的最大数目。这两个功能是 Bell 实验室版 awk 的扩展功能,在标准 awk 中不适用。
|
|
|
|
|
|
|
|
|
|
|
|
-W compact or --compat, -W traditional or --traditional
|
|
|
|
|
|
# 在兼容模式下运行 awk。所以 gawk 的行为和标准的 awk 完全一样,所有的 awk 扩展都被忽略。
|
|
|
|
|
|
|
|
|
|
|
|
-W copyleft or --copyleft, -W copyright or --copyright
|
|
|
|
|
|
# 打印简短的版权信息。
|
|
|
|
|
|
|
|
|
|
|
|
-W help or --help, -W usage or --usage
|
|
|
|
|
|
# 打印全部 awk 选项和每个选项的简短说明。
|
|
|
|
|
|
|
|
|
|
|
|
-W lint or --lint
|
|
|
|
|
|
# 打印不能向传统 unix 平台移植的结构的警告。
|
|
|
|
|
|
|
|
|
|
|
|
-W lint-old or --lint-old
|
|
|
|
|
|
# 打印关于不能向传统 unix 平台移植的结构的警告。
|
|
|
|
|
|
|
|
|
|
|
|
-W posix
|
|
|
|
|
|
# 打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当 fs 是一个空格时,将新行作为一个域分隔符;操作符 ** 和 **= 不能代替 ^ 和 ^=;fflush无效。
|
|
|
|
|
|
|
|
|
|
|
|
-W re-interval or --re-inerval
|
|
|
|
|
|
# 允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。
|
|
|
|
|
|
|
|
|
|
|
|
-W source program-text or --source program-text
|
|
|
|
|
|
# 使用 program-text 作为源代码,可与 -f 命令混用。
|
|
|
|
|
|
|
|
|
|
|
|
-W version or --version
|
|
|
|
|
|
# 打印 bug 报告信息的版本。
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
### 5. 格式化打印
|
|
|
|
|
|
|
|
|
|
|
|
- print 和 printf 都是打印输出的,不过两者用法和显示上有些不同而已。
|
|
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
|
print 格式:print item1,item2, ...
|
|
|
|
|
|
printf格式:printf “FORMAT ”,item1,item2, ...
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
- 逗号为分隔符时,显示的是空格;
|
|
|
|
|
|
- 分隔符分隔的字段(域)标记称为域标识,用$0,$1,$2,...,$n表示,其中$0 为所有域,$1就是表示第一个字段(域),以此类推;
|
|
|
|
|
|
|
|
|
|
|
|
- 输出的各item可以字符串,也可以是数值,当前记录的字段,变量或awk 的表达式等;
|
|
|
|
|
|
|
|
|
|
|
|
- 如果省略了item ,相当于print $0
|
|
|
|
|
|
|
|
|
|
|
|
- 对于printf来说,其中格式化字符串包括两部分内容: 一部分是正常字符,这些字符将按原样输出; 另一部分是格式化规定字符, 以 **%** 开始, 后跟一个或几个规定字符,用来确定输出内容格式,必须指定 FORMAT,即必须指出后面每个itemsN 的输出格式,**printf** 时默认是不会换行的,而 **print** 函数默认会在每行后面加上 **\n** 换行符
|
|
|
|
|
|
|
|
|
|
|
|
| **格式符** | **说明** |
|
|
|
|
|
|
| :--------: | :----------------------------------------------------------: |
|
|
|
|
|
|
| %d | 十进制有符号整数 |
|
|
|
|
|
|
| %u | 十进制无符号整数 |
|
|
|
|
|
|
| %f | 浮点数 |
|
|
|
|
|
|
| %s | 字符串 |
|
|
|
|
|
|
| %c | 单个字符 |
|
|
|
|
|
|
| %p | 指针的值 |
|
|
|
|
|
|
| %e | 指数形式的浮点数 |
|
|
|
|
|
|
| %x | %X 无符号以十六进制表示的整数 |
|
|
|
|
|
|
| %o | 无符号以八进制表示的整数 |
|
|
|
|
|
|
| %g | 自动选择合适的表示法 |
|
|
|
|
|
|
| %% | 显示%自身 |
|
|
|
|
|
|
| #[.#] | 第一个数字控制显示的宽度;第二个#表示小数点后精度,%3.1f |
|
|
|
|
|
|
| - | 左对齐(默认右对齐);%-15s,就是以左对齐方式显示15个字符长度 |
|
|
|
|
|
|
| + | 显示数值的正负符号 %+d |
|
|
|
|
|
|
|
|
|
|
|
|
**示例:**
|
|
|
|
|
|
|
|
|
|
|
|
```bash
|
|
|
|
|
|
# print 函数
|
|
|
|
|
|
[root@wxin ~]# awk '{print "hello,awk"}'
|
|
|
|
|
|
[root@wxin ~]# awk –F: '{print}' /etc/passwd
|
|
|
|
|
|
[root@wxin ~]# awk –F: ‘{print “wang”}’ /etc/passwd
|
|
|
|
|
|
[root@wxin ~]# awk –F: ‘{print $1}’ /etc/passwd
|
|
|
|
|
|
[root@wxin ~]# awk –F: ‘{print $0}’ /etc/passwd
|
|
|
|
|
|
[root@wxin ~]# awk –F: ‘{print $1”\t”$3}’ /etc/passwd
|
|
|
|
|
|
[root@wxin ~]# date |awk '{print "Month: " $2 "\nYear: " $NF}'
|
|
|
|
|
|
[root@wxin ~]# awk -F: '{print "username is: " $1 "\t uid is: " $3}' /etc/passwd
|
|
|
|
|
|
[root@wxin ~]# awk -F: '{print "\tusername and uid: " $1,$3 "!"}' /etc/passwd
|
|
|
|
|
|
|
|
|
|
|
|
# printf函数
|
|
|
|
|
|
[root@wxin ~]# tail –3 /etc/fstab |awk ‘{print $2,$4}’
|
|
|
|
|
|
[root@wxin ~]# awk -F: '{printf "%-15s %-10s %-15s\n", $1,$2,$3}' /etc/passwd
|
|
|
|
|
|
[root@wxin ~]# awk -F: '{printf "|%-15s| %-10s| %-15s|\n", $1,$2,$3}' /etc/passwd
|
|
|
|
|
|
[root@wxin ~]# awk -F: ‘{printf "%s",$1}’ /etc/passwd
|
|
|
|
|
|
[root@wxin ~]# awk -F: ‘{printf "%s\n",$1}’ /etc/passwd
|
|
|
|
|
|
[root@wxin ~]# awk -F: '{printf "%-20s %10d\n",$1,$3}' /etc/passwd
|
|
|
|
|
|
[root@wxin ~]# awk -F: ‘{printf "Username: %s\n",$1}’ /etc/passwd
|
|
|
|
|
|
[root@wxin ~]# awk -F: ‘{printf “Username: %s,UID:%d\n",$1,$3}’ /etc/passwd
|
|
|
|
|
|
[root@wxin ~]# awk -F: ‘{printf "Username: %15s,UID:%d\n",$1,$3}’ /etc/passwd
|
|
|
|
|
|
[root@wxin ~]# awk -F: ‘{printf "Username: %-15s,UID:%d\n",$1,$3}’ /etc/passwd
|
|
|
|
|
|
[root@wxin ~]# lsmod | awk -v FS=" " 'BEGIN{printf "%s %26s %10s\n","Module","Size","Used by"}{printf "%-20s %13d %5s %s\n",$1,$2,$3,$4}' /proc/modules
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
### 6. awk 运算符
|
|
|
|
|
|
|
|
|
|
|
|
| 运算符 | 描述 |
|
|
|
|
|
|
| :---------------------: | :------------------------------: |
|
|
|
|
|
|
| = += -= *= /= %= ^= **= | 赋值 |
|
|
|
|
|
|
| ?: | C条件表达式 |
|
|
|
|
|
|
| \|\| | 逻辑或 |
|
|
|
|
|
|
| && | 逻辑与 |
|
|
|
|
|
|
| ~ 和 !~ | 匹配正则表达式和不匹配正则表达式 |
|
|
|
|
|
|
| < <= > >= != == | 关系运算符 |
|
|
|
|
|
|
| 空格 | 连接 |
|
|
|
|
|
|
| + - | 加,减 |
|
|
|
|
|
|
| * / % | 乘,除与求余 |
|
|
|
|
|
|
| + - ! | 一元加,减和逻辑非 |
|
|
|
|
|
|
| ^ *** | 求幂 |
|
|
|
|
|
|
| ++ -- | 增加或减少,作为前缀或后缀 |
|
|
|
|
|
|
| $ | 字段引用 |
|
|
|
|
|
|
| in | 数组成员 |
|
|
|
|
|
|
|
|
|
|
|
|
**示例:**
|
|
|
|
|
|
|
|
|
|
|
|
过滤第一列大于2的行
|
|
|
|
|
|
|
|
|
|
|
|
```bash
|
|
|
|
|
|
[root@wxin ~]# awk '$1>2' log.txt
|
|
|
|
|
|
3 Are you like awk
|
|
|
|
|
|
This's a test
|
|
|
|
|
|
10 There are orange,apple,mongo
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
过滤第一列等于2的行
|
|
|
|
|
|
|
|
|
|
|
|
```bash
|
|
|
|
|
|
[root@wxin ~]# awk '$1==2 {print $1,$3}' log.txt
|
|
|
|
|
|
2 is
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
过滤第一列大于2并且第二列等于'Are'的行
|
|
|
|
|
|
|
|
|
|
|
|
```bash
|
|
|
|
|
|
[root@wxin ~]# awk '$1>2 && $2=="Are" {print $1,$2,$3}' log.txt
|
|
|
|
|
|
3 Are you
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
过滤练习
|
|
|
|
|
|
|
|
|
|
|
|
```bash
|
|
|
|
|
|
[root@wxin ~]# awk -F: '$3 == 0' /etc/passwd
|
|
|
|
|
|
[root@wxin ~]# awk -F: '$3 < 10' /etc/passwd
|
|
|
|
|
|
[root@wxin ~]# awk -F: '$NF == "/bin/bash"' /etc/passwd
|
|
|
|
|
|
[root@wxin ~]# awk -F: '$1 == "alice"' /etc/passwd
|
|
|
|
|
|
[root@wxin ~]# awk -F: '$1 ~ /alic/ ' /etc/passwd
|
|
|
|
|
|
[root@wxin ~]# awk -F: '$1 !~ /alic/ ' /etc/passwd
|
|
|
|
|
|
[root@wxin ~]# df -P | grep '/' |awk '$4 > 25000'
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
### 7. awk 变量
|
|
|
|
|
|
|
|
|
|
|
|
**`awk`内置变量**
|
|
|
|
|
|
|
|
|
|
|
|
| 变量 | 描述 |
|
|
|
|
|
|
| :---------: | :--------------------------------------------------------: |
|
|
|
|
|
|
| $n | 当前记录的第n个字段,字段间由FS分隔 |
|
|
|
|
|
|
| $0 | 完整的输入记录 |
|
|
|
|
|
|
| ARGC | 命令行参数的数目 |
|
|
|
|
|
|
| ARGIND | 命令行中当前文件的位置(从0开始算) |
|
|
|
|
|
|
| ARGV | 包含命令行参数的数组 |
|
|
|
|
|
|
| CONVFMT | 数字转换格式(默认值为%.6g)ENVIRON环境变量关联数组 |
|
|
|
|
|
|
| ERRNO | 最后一个系统错误的描述 |
|
|
|
|
|
|
| FIELDWIDTHS | 字段宽度列表(用空格键分隔) |
|
|
|
|
|
|
| FILENAME | 当前文件名 |
|
|
|
|
|
|
| FNR | 各文件分别计数的行号 |
|
|
|
|
|
|
| FS | 字段分隔符(默认是任何空格) |
|
|
|
|
|
|
| IGNORECASE | 如果为真,则进行忽略大小写的匹配 |
|
|
|
|
|
|
| NF | 一条记录的字段的数目 |
|
|
|
|
|
|
| NR | 已经读出的记录数,就是行号,从1开始 |
|
|
|
|
|
|
| OFMT | 数字的输出格式(默认值是%.6g) |
|
|
|
|
|
|
| OFS | 输出记录分隔符(输出换行符),输出时用指定的符号代替换行符 |
|
|
|
|
|
|
| ORS | 输出记录分隔符(默认值是一个换行符) |
|
|
|
|
|
|
| RLENGTH | 由match函数所匹配的字符串的长度 |
|
|
|
|
|
|
| RS | 记录分隔符(默认是一个换行符) |
|
|
|
|
|
|
| RSTART | 由match函数所匹配的字符串的第一个位置 |
|
|
|
|
|
|
| SUBSEP | 数组下标分隔符(默认值是/034) |
|
|
|
|
|
|
|
|
|
|
|
|
**示例:**
|
|
|
|
|
|
|
|
|
|
|
|
```bash
|
|
|
|
|
|
[root@wxin ~]# awk -F: '{print $0}' /etc/passwd # $0
|
|
|
|
|
|
[root@wxin ~]# awk -F: '{print NR, $0}' /etc/passwd /etc/hosts # NR
|
|
|
|
|
|
[root@wxin ~]# awk -F: '{print FNR, $0}' /etc/passwd /etc/hosts # FNR
|
|
|
|
|
|
[root@wxin ~]# awk -F: '{print $0,NF}' /etc/passwd # NF
|
|
|
|
|
|
[root@wxin ~]# awk -F: '/alice/{print $1, $3}' /etc/passwd # FS
|
|
|
|
|
|
[root@wxin ~]# awk -F'[ :\t]' '{print $1,$2,$3}' /etc/passwd
|
|
|
|
|
|
[root@wxin ~]# awk 'BEGIN{FS=":"} {print $1,$3}' /etc/passwd
|
|
|
|
|
|
[root@wxin ~]# awk -F: '/alice/{print $1,$2,$3,$4}' /etc/passwd # OFS
|
|
|
|
|
|
[root@wxin ~]# awk 'BEGIN{FS=":"; OFS="+++"} /^root/{print $1,$2,$3,$4}' passwd
|
|
|
|
|
|
[root@wxin ~]# awk -F: 'BEGIN{RS=" "} {print $0}' a.txt # RS
|
|
|
|
|
|
[root@wxin ~]# awk -F: 'BEGIN{ORS=""} {print $0}' passwd # ORS
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
- 字段分隔符: FS OFS 默认空格或制表符
|
|
|
|
|
|
- 记录分隔符: RS ORS 默认换行符
|
|
|
|
|
|
|
|
|
|
|
|
```bash
|
|
|
|
|
|
# ORS 默认输出一条记录应该回车,加了一个空格
|
|
|
|
|
|
[root@wxin ~]# awk 'BEGIN{ORS=" "} {print $0}' /etc/passwd # 将文件每一行合并为一行
|
|
|
|
|
|
|
|
|
|
|
|
[root@wxin ~]# head -1 /etc/passwd > passwd1
|
|
|
|
|
|
[root@wxin ~]# cat passwd1
|
|
|
|
|
|
root:x:0:0:root:/root:/bin/bash
|
|
|
|
|
|
[root@wxin ~]# awk 'BEGIN{RS=":"} {print $0}' passwd1
|
|
|
|
|
|
root
|
|
|
|
|
|
x
|
|
|
|
|
|
0
|
|
|
|
|
|
0
|
|
|
|
|
|
root
|
|
|
|
|
|
/root
|
|
|
|
|
|
/bin/bash
|
|
|
|
|
|
|
|
|
|
|
|
[root@wxin ~]# awk 'BEGIN{RS=":"} {print $0}' passwd1 |grep -v '^$' > passwd2
|
|
|
|
|
|
|
|
|
|
|
|
# 输出顺序号 NR, 匹配文本行号
|
|
|
|
|
|
[root@wxin ~]# awk '{print NR,FNR,$1,$2,$3}' /etc/passwd
|
|
|
|
|
|
1 1 root:x:0:0:root:/root:/bin/bash
|
|
|
|
|
|
2 2 bin:x:1:1:bin:/bin:/sbin/nologin
|
|
|
|
|
|
3 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
|
|
|
|
|
|
4 4 adm:x:3:4:adm:/var/adm:/sbin/nologin
|
|
|
|
|
|
5 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
|
|
|
|
|
|
|
|
|
|
|
|
# 指定输出分割符
|
|
|
|
|
|
[root@wxin ~]# awk '{print $1,$2,$5}' OFS=" $ " /etc/passwd
|
|
|
|
|
|
root:x:0:0:root:/root:/bin/bash $ $
|
|
|
|
|
|
bin:x:1:1:bin:/bin:/sbin/nologin $ $
|
|
|
|
|
|
daemon:x:2:2:daemon:/sbin:/sbin/nologin $ $
|
|
|
|
|
|
adm:x:3:4:adm:/var/adm:/sbin/nologin $ $
|
|
|
|
|
|
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin $ $
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
**`awk`自定义变量(区分大小写)**
|
|
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
|
在'{...}'前,需要用-v var=value:awk -v var=value '{...}'
|
|
|
|
|
|
在program 中直接定义:awk '{var=vlue}'
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
**`awk`使用外部变量**
|
|
|
|
|
|
|
|
|
|
|
|
在双引号的情况下使用
|
|
|
|
|
|
|
|
|
|
|
|
```bash
|
|
|
|
|
|
[root@wxin ~]# var="bash"
|
|
|
|
|
|
[root@wxin ~]# echo "unix script" |awk "gsub(/unix/,\"$var\")"
|
|
|
|
|
|
bash script
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
在单引号的情况下使用
|
|
|
|
|
|
|
|
|
|
|
|
```bash
|
|
|
|
|
|
[root@wxin ~]# var="bash"
|
|
|
|
|
|
[root@wxin ~]# echo "unix script" |awk 'gsub(/unix/,"'"$var"'")'
|
|
|
|
|
|
bash script
|
|
|
|
|
|
|
|
|
|
|
|
[root@wxin ~]# df -h
|
|
|
|
|
|
Filesystem Size Used Avail Use% Mounted on
|
|
|
|
|
|
/dev/mapper/cl-root 2.8T 246G 2.5T 9% /
|
|
|
|
|
|
tmpfs 24G 20K 24G 1% /dev/shm
|
|
|
|
|
|
/dev/sda2 1014M 194M 821M 20% /boot
|
|
|
|
|
|
|
|
|
|
|
|
[root@wxin ~]# df -h |awk '{ if(int($5)>5){print $6":"$5} }'
|
|
|
|
|
|
/:9%
|
|
|
|
|
|
/boot:20%
|
|
|
|
|
|
|
|
|
|
|
|
[root@wxin ~]# i=10
|
|
|
|
|
|
[root@wxin ~]# df -h |awk '{ if(int($5)>'''$i'''){print $6":"$5} }'
|
|
|
|
|
|
/boot:20%
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
AWK 参数-v(建议)
|
|
|
|
|
|
|
|
|
|
|
|
```bash
|
|
|
|
|
|
[root@wxin ~]# echo "unix script" |awk -v var="bash" 'gsub(/unix/,var)'
|
|
|
|
|
|
bash script
|
|
|
|
|
|
|
|
|
|
|
|
[root@wxin ~]# awk -v user=root -F: '$1 == user' /etc/passwd
|
|
|
|
|
|
root:x:0:0:root:/root:/bin/bash
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
### 8. awk 脚本
|
|
|
|
|
|
|
|
|
|
|
|
**`awk`脚本定义格式**
|
|
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
|
格式1:
|
|
|
|
|
|
BEGIN{} pattern{} END{}
|
|
|
|
|
|
|
|
|
|
|
|
格式2:
|
|
|
|
|
|
#!/bin/awk -f
|
|
|
|
|
|
#add 'x' right
|
|
|
|
|
|
BEGIN{} pattern{} END{}
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
关于awk 脚本,需要注意两个关键词BEGIN和END。
|
|
|
|
|
|
|
|
|
|
|
|
- BEGIN{ 这里面放的是执行前的语句 }
|
|
|
|
|
|
- END {这里面放的是处理完所有的行后要执行的语句 }
|
|
|
|
|
|
- {这里面放的是处理每一行时要执行的语句}
|
|
|
|
|
|
|
|
|
|
|
|
- 格式1假设为`f1.awk`文件,格式2假设为`f2.awk`文件
|
|
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
|
awk [-v var=value] f1.awk [file]
|
|
|
|
|
|
f2.awk [-v var=value] [var1=value1] [file]
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
- awk [-v var=value] f1.awk [file],把处理阶段放到一个文件而已,展开后就是普通的`awk`语句。
|
|
|
|
|
|
- f2.awk [-v var=value] [var1=value1] [file] 中 [-v var=value] 是在`BEGIN`之前设置的变量值,[var1=value1]是在BEGIN过程之后进行的,也就是说直到首行输入完成后,这个变量才可用。
|
|
|
|
|
|
|
|
|
|
|
|
**示例:**
|
|
|
|
|
|
|
|
|
|
|
|
示例一:
|
|
|
|
|
|
|
|
|
|
|
|
创建一个文件(学生成绩表)
|
|
|
|
|
|
|
|
|
|
|
|
```bash
|
|
|
|
|
|
[root@wxin ~]# cat score.txt
|
|
|
|
|
|
Marry 2143 78 84 77
|
|
|
|
|
|
Jack 2321 66 78 45
|
|
|
|
|
|
Tom 2122 48 77 71
|
|
|
|
|
|
Mike 2537 87 97 95
|
|
|
|
|
|
Bob 2415 40 57 62
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
定义 awk 脚本
|
|
|
|
|
|
|
|
|
|
|
|
```bash
|
|
|
|
|
|
[root@wxin ~]# cat cal.awk
|
|
|
|
|
|
#!/bin/awk -f
|
|
|
|
|
|
#运行前
|
|
|
|
|
|
BEGIN {
|
|
|
|
|
|
math = 0
|
|
|
|
|
|
english = 0
|
|
|
|
|
|
computer = 0
|
|
|
|
|
|
|
|
|
|
|
|
printf "NAME NO. MATH ENGLISH COMPUTER TOTAL\n"
|
|
|
|
|
|
printf "---------------------------------------------\n"
|
|
|
|
|
|
}
|
|
|
|
|
|
#运行中
|
|
|
|
|
|
{
|
|
|
|
|
|
math+=$3
|
|
|
|
|
|
english+=$4
|
|
|
|
|
|
computer+=$5
|
|
|
|
|
|
printf "%-6s %-6s %4d %8d %8d %8d\n", $1, $2, $3,$4,$5, $3+$4+$5
|
|
|
|
|
|
}
|
|
|
|
|
|
#运行后
|
|
|
|
|
|
END {
|
|
|
|
|
|
printf "---------------------------------------------\n"
|
|
|
|
|
|
printf " TOTAL:%10d %8d %8d \n", math, english, computer
|
|
|
|
|
|
printf "AVERAGE:%10.2f %8.2f %8.2f\n", math/NR, english/NR, computer/NR
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
[root@wxin ~]# awk -f cal.awk score.txt
|
|
|
|
|
|
NAME NO. MATH ENGLISH COMPUTER TOTAL
|
|
|
|
|
|
---------------------------------------------
|
|
|
|
|
|
Marry 2143 78 84 77 239
|
|
|
|
|
|
Jack 2321 66 78 45 189
|
|
|
|
|
|
Tom 2122 48 77 71 196
|
|
|
|
|
|
Mike 2537 87 97 95 279
|
|
|
|
|
|
Bob 2415 40 57 62 159
|
|
|
|
|
|
---------------------------------------------
|
|
|
|
|
|
TOTAL: 319 393 350
|
|
|
|
|
|
AVERAGE: 63.80 78.60 70.00
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
示例二:
|
|
|
|
|
|
|
|
|
|
|
|
```bash
|
|
|
|
|
|
[root@wxin ~]# vim f1.awk
|
|
|
|
|
|
{if($3>=1000)print $1,$3}
|
|
|
|
|
|
awk -F: -f f1.awk /etc/passwd
|
|
|
|
|
|
|
|
|
|
|
|
[root@wxin ~]# vim f2.awk
|
|
|
|
|
|
#!/bin/awk –f
|
|
|
|
|
|
# this is a awk script
|
|
|
|
|
|
{if($3>=1000)print $1,$3}
|
|
|
|
|
|
# chmod +x f2.awk
|
|
|
|
|
|
f2.awk –F: /etc/passwd
|
|
|
|
|
|
|
|
|
|
|
|
[root@wxin ~]# vim test.awk
|
|
|
|
|
|
#!/bin/awk –f
|
|
|
|
|
|
{if($3 >=min && $3<=max)print $1,$3}
|
|
|
|
|
|
#chmod +x test.awk
|
|
|
|
|
|
test.awk -F: min=100 max=200 /etc/passwd
|
|
|
|
|
|
```
|
|
|
|
|
|
|