33 KiB
消息队列集群-RabbitMQ
一:消息队列
1. 简介
MQ 全称为(Message Queue消息队列)。是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。
消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信。。队列的使用除去了接收和发送应用程序同时执行的要求。
当下主流的消息中间件有RabbitMQ、Kafka、ActiveMQ、RocketMQ等。其能在不同平台之间进行通信,常用来屏蔽各种平台协议之间的特性,实现应用程序之间的协同。优点在于能够在客户端和服务器之间进行同步和异步的连接,并且在任何时刻都可以将消息进行传送和转发,是分布式系统中非常重要的组件,主要用来解决应用耦合、异步通信、流量削峰等问题。
2. 消息队列作用
作用:
- 解耦
- 冗余(存储)
- 扩展性
- 削峰
- 可恢复性
- 顺序保证
- 缓冲
- 异步通信
应用场景:
**解耦:**将应用进行解耦
具体场景:用户下单后,订单系统需要通知库存系统
传统做法(传统模式的缺点:假如库存系统无法访问,则订单减库存将失败,从而导致订单失败,订单系统与库存系统耦合)
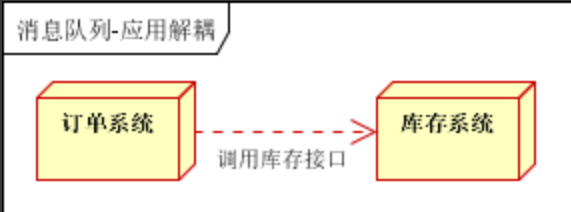
使用消息队列
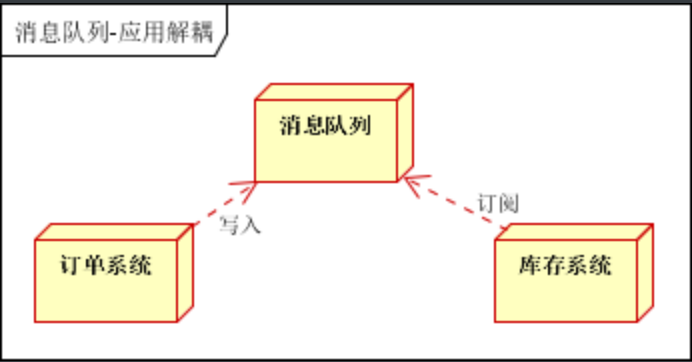
订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户订单下单成功
库存系统:订阅下单的消息,采用拉/推的方式,获取下单信息,库存系统根据下单信息,进行库存操作
假如:在下单时库存系统不能正常使用。也不影响正常下单,因为下单后,订单系统写入消息队列就不再关心其他的后续操作了。实现订单系统与库存系统的应用解耦
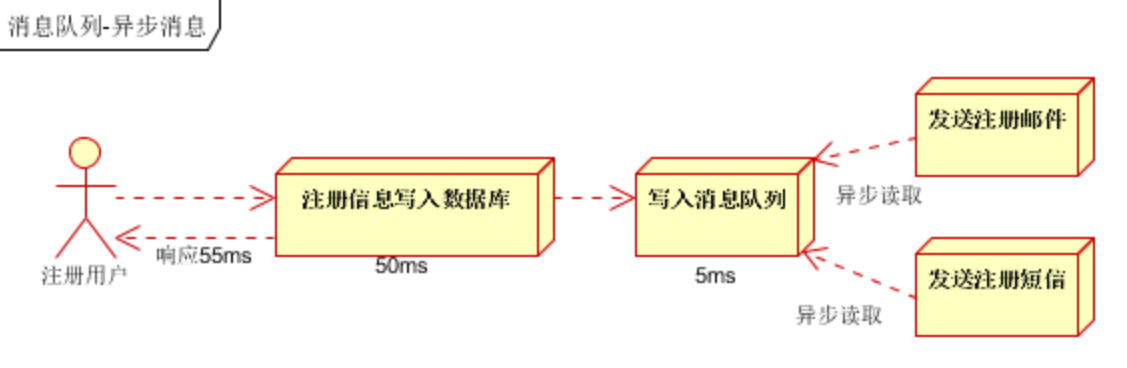
**异步处理:**多应用对消息队列中同一消息进行处理,应用间并发处理消息,相比串行处理,减少处理时间
具体场景:用户为了使用某个应用,进行注册,系统需要发送注册邮件并验证短信
1)串行方式:新注册信息生成后,先发送注册邮件,再发送验证短信
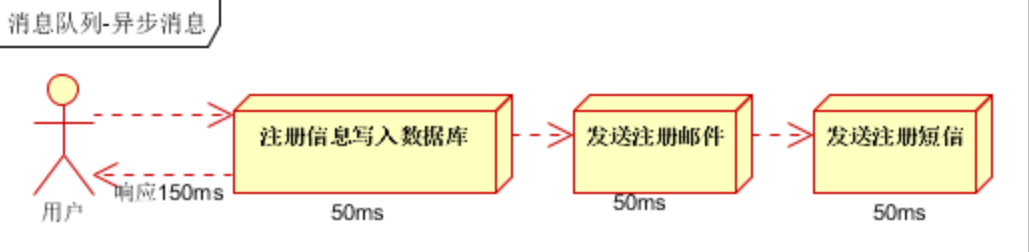
2)并行处理:新注册信息写入后,由发短信和发邮件并行处理
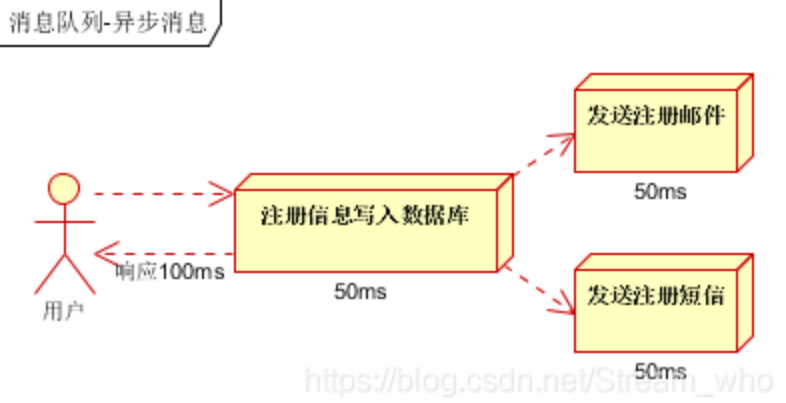
3)若使用消息队列:在写入消息队列后立即返回成功给客户端,则总的响应时间依赖于写入消息队列的时间,而写入消息队列的时间本身是可以很快的,基本可以忽略不计,因此总的处理时间相比串行提高了2倍,相比并行提高了一倍
**限流削峰:**广泛应用于秒杀或抢购活动中,避免流量过大导致应用系统挂掉的情况
具体场景:秒杀活动,一般会因为流量过大,导致流量暴增,应用挂掉。为解决这个问题,一般需要在应用前端加入消息队列
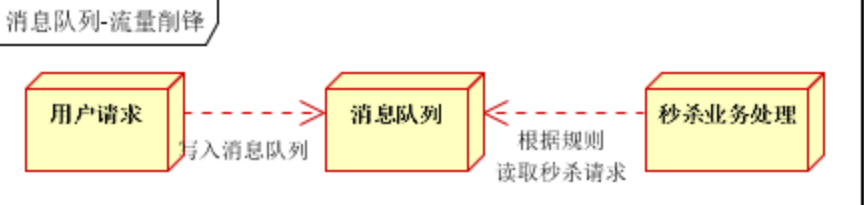
1)作用:
- 可以控制活动的人数
- 可以缓解短时间内高流量压垮应用
2)用户的请求,服务器接收后,首先写入消息队列。假如消息队列长度超过最大数量,则直接抛弃用户请求或跳转到错误页面
3)秒杀业务根据消息队列中的请求信息,再做后续处理
日志处理:日志处理是指将消息队列用在日志处理中,比如Kafka的应用,解决大量日志传输的问题
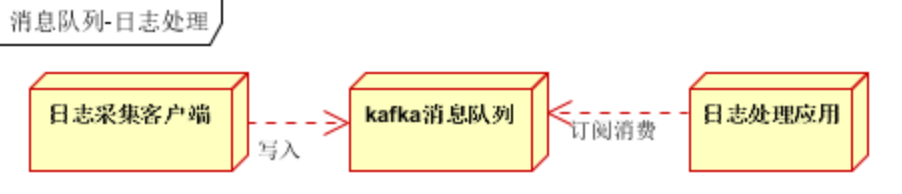
1)日志采集客户端,负责日志数据采集,定时写受写入Kafka队列
2)Kafka消息队列,负责日志数据的接收,存储和转发
3)日志处理应用:订阅并消费kafka队列中的日志数据
消息通讯:消息通讯是指,消息队列一般都内置了高效的通信机制,因此也可以用在纯的消息通讯
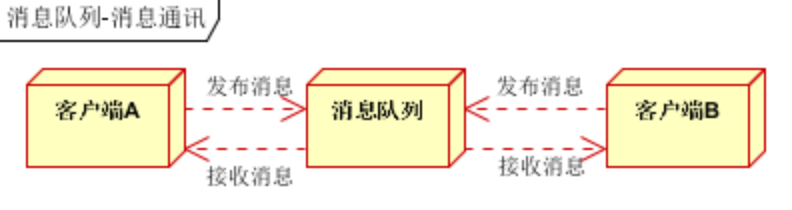
1)点对点通讯(客户端A和客户端B使用同一队列,进行消息通讯)
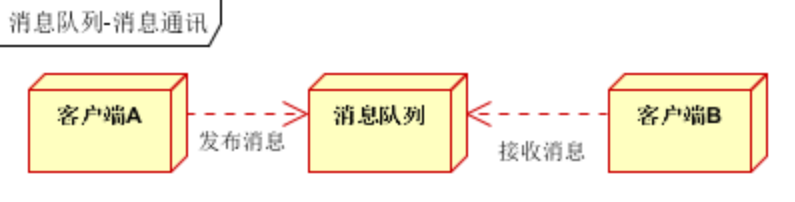
2)聊天时通讯(客户端A,客户端B,客户端N订阅同一主题,进行消息发布和接收。实现类似聊天室效果)
3. 消息队列模式
点对点模式
P2P模式包含三个角色:消息队列(Queue)、发送者(Sender)、接收者(Receiver)。每个消息都被发送到一个特定的队列,接收者从队列中获取消息。队列保留着消息,直到它们被消费或超时。
特点:
- 每个消息只有一个消费者(Consumer),即一旦被消费,消息就不再在消息队列中
- 发送者和接收者之间在时间上没有依赖性,也就是说当发送者发送了消息之后,不管接收者有没有正在运行它不会影响到消息被发送到队列
- 接收者在成功接收消息之后需向队列应答成功,以便消息队列删除当前接收的消息
- 如果希望发送的每个消息都会被成功处理的话,那么需要P2P模式
发布 / 订阅模式
Pub/Sub模式包含三个角色:主题(Topic)、发布者(Publisher)、订阅者(Subscriber) 。多个发布者将消息发送到Topic,系统将这些消息传递给多个订阅者。
特点:
- 每个消息可以有多个订阅者
- 发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息
- 为了消费消息,订阅者需要提前订阅该角色主题,并保持在线运行
- 如果希望发送的消息可以不被做任何处理、或者只被一个消费者处理、或者可以被多个消费者处理的话,那么可以采用Pub/Sub模式
4. 常见的消息队列
RabbitMQ:
RabbitMQ 2007年发布,是一个在AMQP(高级消息队列协议)基础上完成的,可复用的企业消息系统,是当前最主流的消息中间件之一
主要特性:
-
可靠性:提供了多种技术可以让你在性能和可靠性之间进行权衡。这些技术包括持久性机制、投递确认、发布者证实和高可用性机制
-
灵活的路由: 消息在到达队列前是通过交换机进行路由的
-
消息集群:在相同局域网中的多个RabbitMQ服务器可以聚合在一起,作为一个独立的逻辑代理来使用
-
队列高可用:队列可以在集群中的机器上进行镜像,以确保在硬件问题下还保证消息安全
-
多种协议的支持:支持多种消息队列协议
-
服务器端用Erlang语言编写,支持只要是你能想到的所有编程语言
-
管理界面:RabbitMQ有一个易用的用户界面,使得用户可以监控和管理消息Broker的许多方面
-
跟踪机制:如果消息异常,RabbitMQ提供消息跟踪机制,使用者可以找出发生了什么
-
插件机制:提供了许多插件,来从多方面进行扩展,也可以编写自己的插件
优点:
- 由于erlang语言的特性,mq 性能较好,高并发
- 健壮、稳定、易用、跨平台、支持多种语言、文档齐全
- 有消息确认机制和持久化机制,可靠性高
- 高度可定制的路由
- 管理界面较丰富,在互联网公司也有较大规模的应用
缺点:
- 尽管结合erlang语言本身的并发优势,性能较好,但是不利于做二次开发和维护
- 实现了代理架构,意味着消息在发送到客户端之前可以在中央节点上排队;使得其运行速度较慢,消息封装后也比较大
- 需要学习比较复杂的接口和协议,学习和维护成本较高
ActiveMQ:
ActiveMQ是由Apache出品,ActiveMQ 是一个完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现。它非常快速,支持多种语言的客户端和协议,而且可以非常容易的嵌入到企业的应用环境中,并有许多高级功能
RocketMQ:
RocketMQ出自阿里公司的开源产品,用 Java 语言实现,在设计时参考了 Kafka,并做出了自己的一些改进,消息可靠性上比 Kafka 更好。RocketMQ在阿里集团被广泛应用在订单,交易,充值,流计算,消息推送,日志流式处理,binglog分发等场景
kafka:
Apache Kafka是一个分布式消息发布订阅系统。它最初由LinkedIn公司基于独特的设计实现为一个分布式的提交日志系统( a distributed commit log),之后成为Apache项目的一部分。Kafka系统快速、可扩展并且可持久化。它的分区特性,可复制和可容错都是其不错的特性
总结:
Kafka在于分布式架构,RabbitMQ基于AMQP协议来实现,RocketMQ/思路来源于kafka,改成了主从结构,在事务性可靠性方面做了优化。广泛来说,电商、金融等对事务性要求很高的,可以考虑RabbitMQ和RocketMQ,对性能要求高的可考虑Kafka
二:RabbitMQ 详解
1. RabbitMQ 介绍
对于一个大型的软件系统来说,它会有很多subsystem or Component or submodule。
那么这些模块是如何通信的?
这和传统的IPC有很大的区别。传统的IPC很多都是在单一系统上的,模块耦合性很大,不适合扩展(Scalability),如果使用socket那么不同的模块的确可以部署到不同的机器上,但还是有很多问题需要解决。
比如: 1)信息的发送者和接收者如何维持这个连接,如果一方的连接中断,这期间的数据如何防止丢失? 2)如何降低发送者和接收者的耦合度? 3)如何让Priority高的接收者先接到数据? 4)如何做到load balance?有效均衡接收者的负载? 5)如何有效的将数据发送到相关的接收者?也就是说将接收者subscribe 不同的数据,如何做有效的filter。 6)如何做到可扩展,甚至将这个通信模块发到cluster上? 7)如何保证接收者接收到了完整,正确的数据?
AMQP协议解决了以上的问题,而RabbitMQ实现了AMQP。
AMQP即Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。
RabbitMQ 是一个在 AMQP(Advanced Message Queuing Protocol )基础上实现的,可复用的企业消息系统。它可以用于大型软件系统各个模块之间的高效通信,支持高并发,支持可扩展。它支持多种客户端如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP等,支持AJAX,持久化,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
RabbitMQ是使用Erlang编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正是如此,使的它变的非常重量级,更适合于企业级的开发。它同时实现了一个Broker构架,这意味着消息在发送给客户端时先在中心队列排队,对路由(Routing)、负载均衡(Load balance)或者数据持久化都有很好的支持。
2. RabbitMQ 概念及工作原理
- **Broker:**简单来说就是消息队列服务器实体。
- **Exchange:**消息交换机,它指定消息按什么规则,路由到哪个队列。
- **Queue:**消息队列载体,每个消息都会被投入到一个或多个队列。
- **Binding:**绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
- **Routing Key:**路由关键字,exchange根据这个关键字进行消息投递。
- **Vhost:**虚拟主机,一个broker里可以开设多个vhost,用作不同用户的消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
- **producer:**消息生产者,就是投递消息的程序。
- **comsumer:**消息消费者,就是接受消息的程序。
- **channel:**消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
RabbitMQ从整体上来看是一个典型的生产者消费者模型,主要负责接收、存储和转发消息
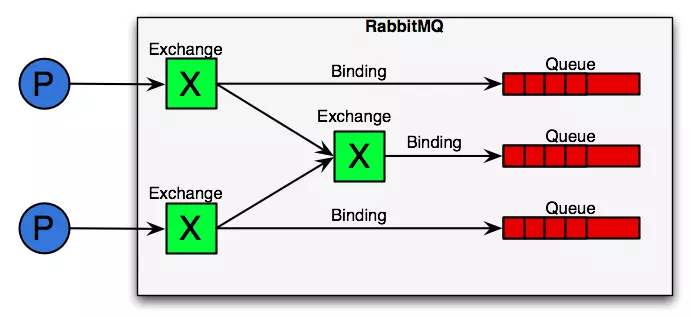
AMQP模型中,消息在producer中产生,发送到MQ的exchange上,exchange根据配置的路由方式发到相应的Queue上,Queue又将消息发送给consumer,消息从queue到consumer有push和pull两种方式。
消息队列的使用过程大概如下:
- 客户端连接到消息队列服务器,打开一个channel。
- 客户端声明一个exchange,并设置相关属性。
- 客户端声明一个queue,并设置相关属性。
- 客户端使用routing key,在exchange和queue之间建立好绑定关系。
- 客户端投递消息到exchange。
exchange接收到消息后,就根据消息的key和已经设置的binding,进行消息路由,将消息投递到一个或多个队列里。 exchange也有几个类型,完全根据key进行投递的叫做Direct交换机,例如,绑定时设置了routing key为"abc",那么客户端提交的消息,只有设置了key为"abc"的才会投递到队列。
三:安装 RabbitMQ
1. 安装
配置yum仓库
[root@rebbitmq ~]# wget -O /etc/yum.repos.d/epel.repo https://mirrors.aliyun.com/repo/epel-7.repo
安装
[root@rebbitmq ~]# yum -y install erlang
[root@rebbitmq ~]# yum -y install rabbitmq-server
rabbitMQ常用命令
启动监控管理器 # rabbitmq-plugins enable rabbitmq_management
关闭监控管理器 # rabbitmq-plugins disable rabbitmq_management
启动rabbitmq # rabbitmq-service start
关闭rabbitmq # rabbitmq-service stop
查看所有的队列 # rabbitmqctl list_queues
清除所有的队列 # rabbitmqctl reset
关闭应用 # rabbitmqctl stop_app
启动应用 # rabbitmqctl start_app
添加用户 # rabbitmqctl add_user username password
分配角色 # rabbitmqctl set_user_tags username administrator
新增虚拟主机 # rabbitmqctl add_vhost vhost_name
将新虚拟主机授权给新用户 # rabbitmqctl set_permissions -p vhost_name username “.*” “.*” “.*” //(后面三个”*”代表用户拥有配置、写、读全部权限)
2. 启动服务
[root@rebbitmq ~]# systemctl start rabbitmq-server.service
4. 配置远程访问
设置用户远程访问
[root@rebbitmq ~]# vim /etc/rabbitmq/rabbitmq.config
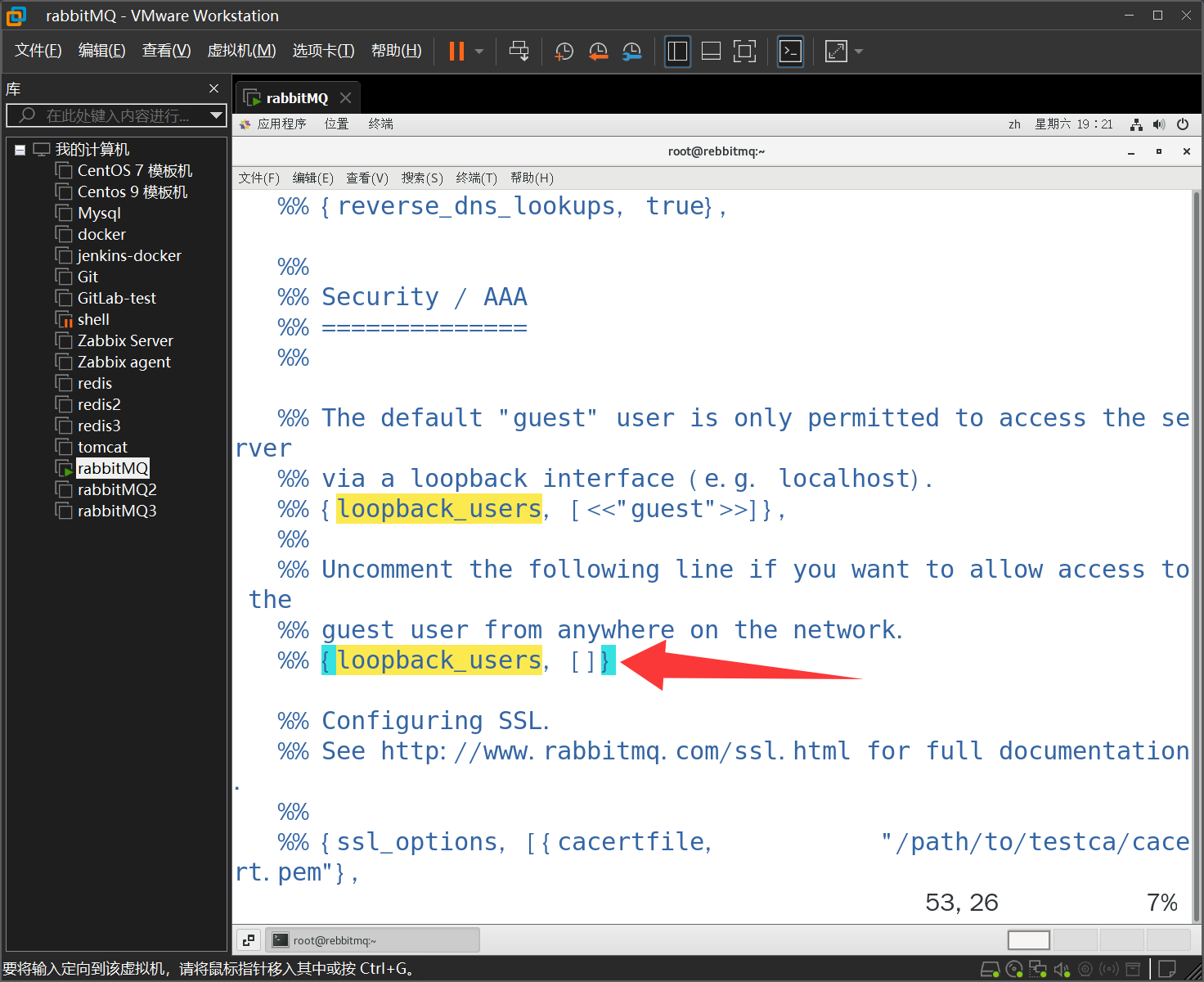
去掉后面的逗号
5. 开启web界面管理工具
[root@rebbitmq ~]# rabbitmq-plugins enable rabbitmq_management
[root@rebbitmq ~]# systemctl restart rabbitmq-server.service
5. 浏览器访问
默认用户名和密码:guest guest
6. 用户管理
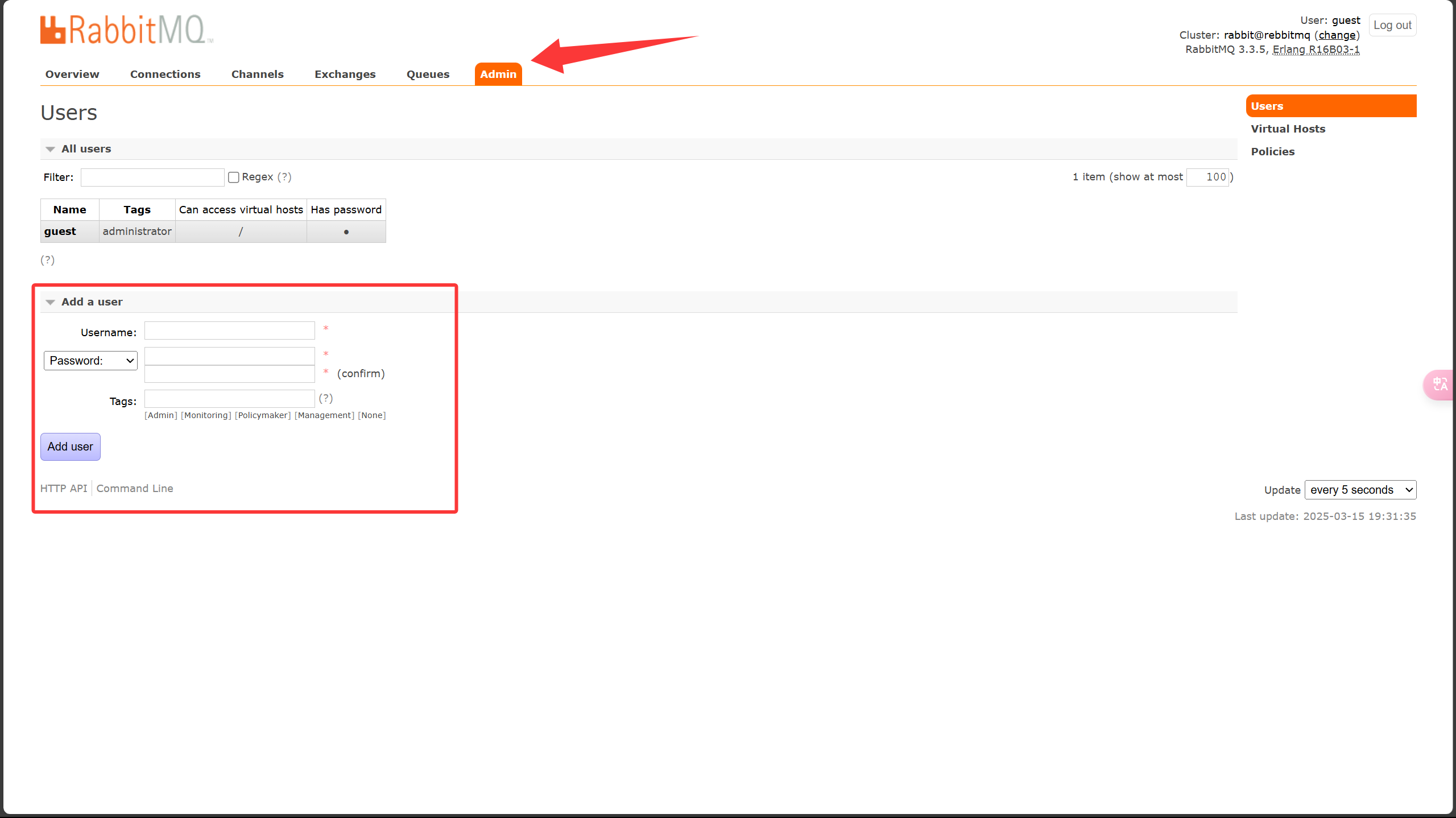
角色
- 超级管理员(administrator):可登陆管理控制台,可查看所有的信息,并且可以对用户,策略(policy)进行操作
- 监控者(monitoring):可登陆管理控制台,同时可以查看rabbitmq节点的相关信息(进程数,内存使用情况,磁盘使用情况等)
- 策略制定者(policymaker):可登陆管理控制台, 同时可以对policy进行管理。但无法查看节点的相关信息
- 普通管理者(management):仅可登陆管理控制台,无法看到节点信息,也无法对策略进行管理
- 其他:无法登陆管理控制台,通常就是普通的生产者和消费者
7. Channels 信号
信道是生产消费者与rabbit通信的渠道,生产者publish或者消费者消费一个队列都是需要通过信道来通信的
信道是建立在TCP上面的虚拟链接,也就是rabbitMQ在一个TCP上面建立成百上千的信道来达到多个线程处理
注意:
为什么RabbitMQ 需要信道,如果直接进行TCP通信呢?
TCP的创建开销很大,创建需要三次握手,销毁需要四次握手
如果不使用信道,那么引用程序就会使用TCP方式进行连接到RabbitMQ,因为MQ可能每秒会进行成千上万的链接
总之就是TCP消耗资源
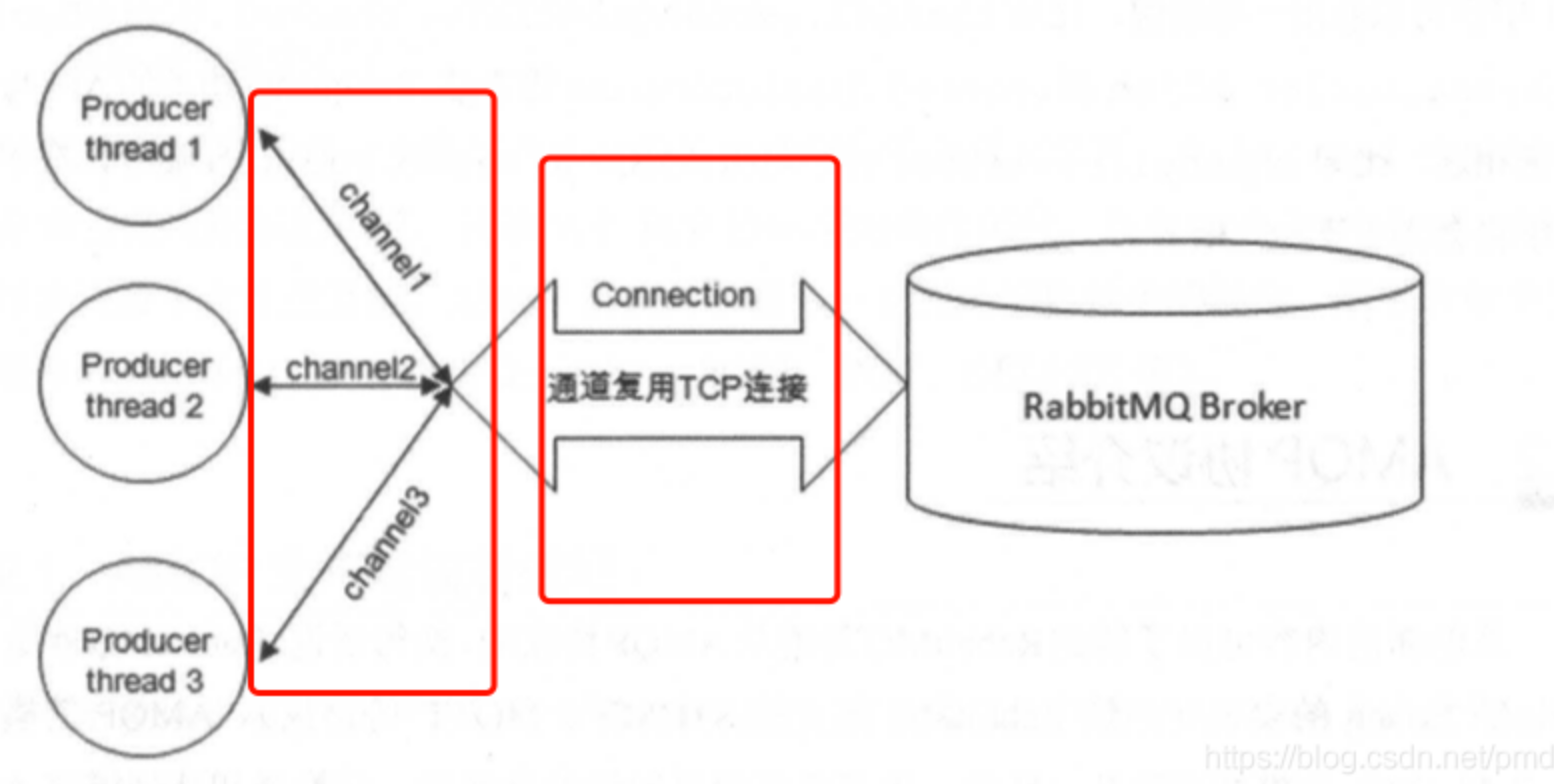
使用rabbitmq时不管是消费还是生产都需要创建信道(channel) 和connection(连接);连接是连接到RabbitMQ的服务器
8. Exchanges 交换
介绍
生产者只能将消息发送到交换机(exchange),交换机工作的内容非常简单,一方面它接收来自生产者的消息,另一方面将它们推入队列;交换机必须确切知道如何处理收到的消息;是应该把这些消息放到特定队列还是说把他们到许多队列中还是说应该丢弃它们;这就的由交换机的类型来决定
类型
- 直接(direct)
- 主题(topic)
- 标题(headers)
- 扇出(fanout)
- 绑定(bindings)
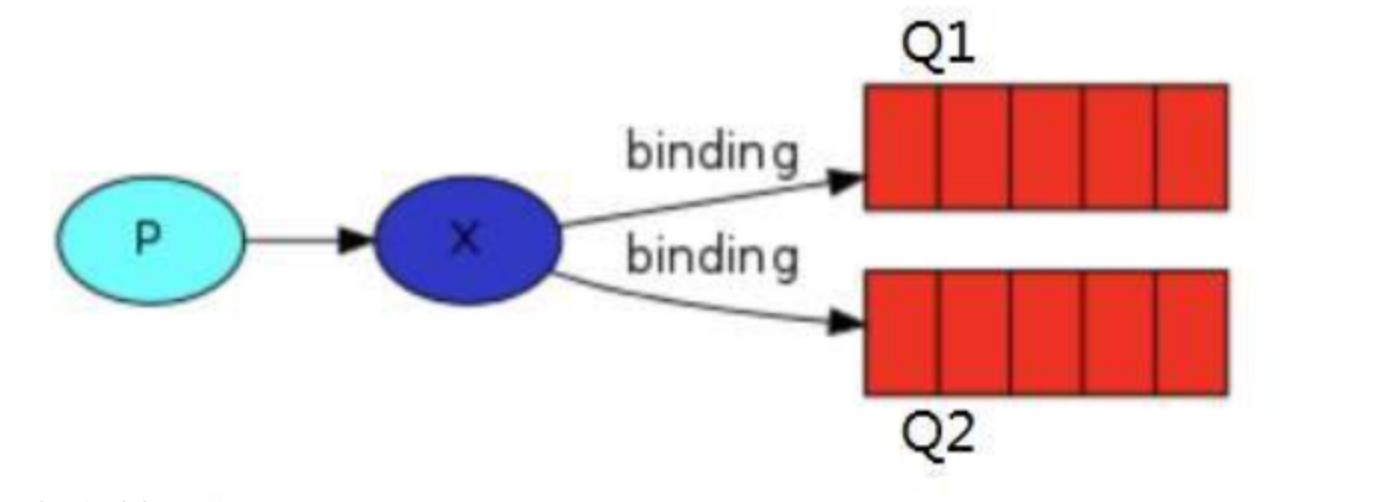
绑定(bindings):
binding 其实是 exchange 和 queue 之间的桥梁,它告诉我们 exchange 和那个队列进行了绑定关系( X 与 Q1 和 Q2 进行了绑定)
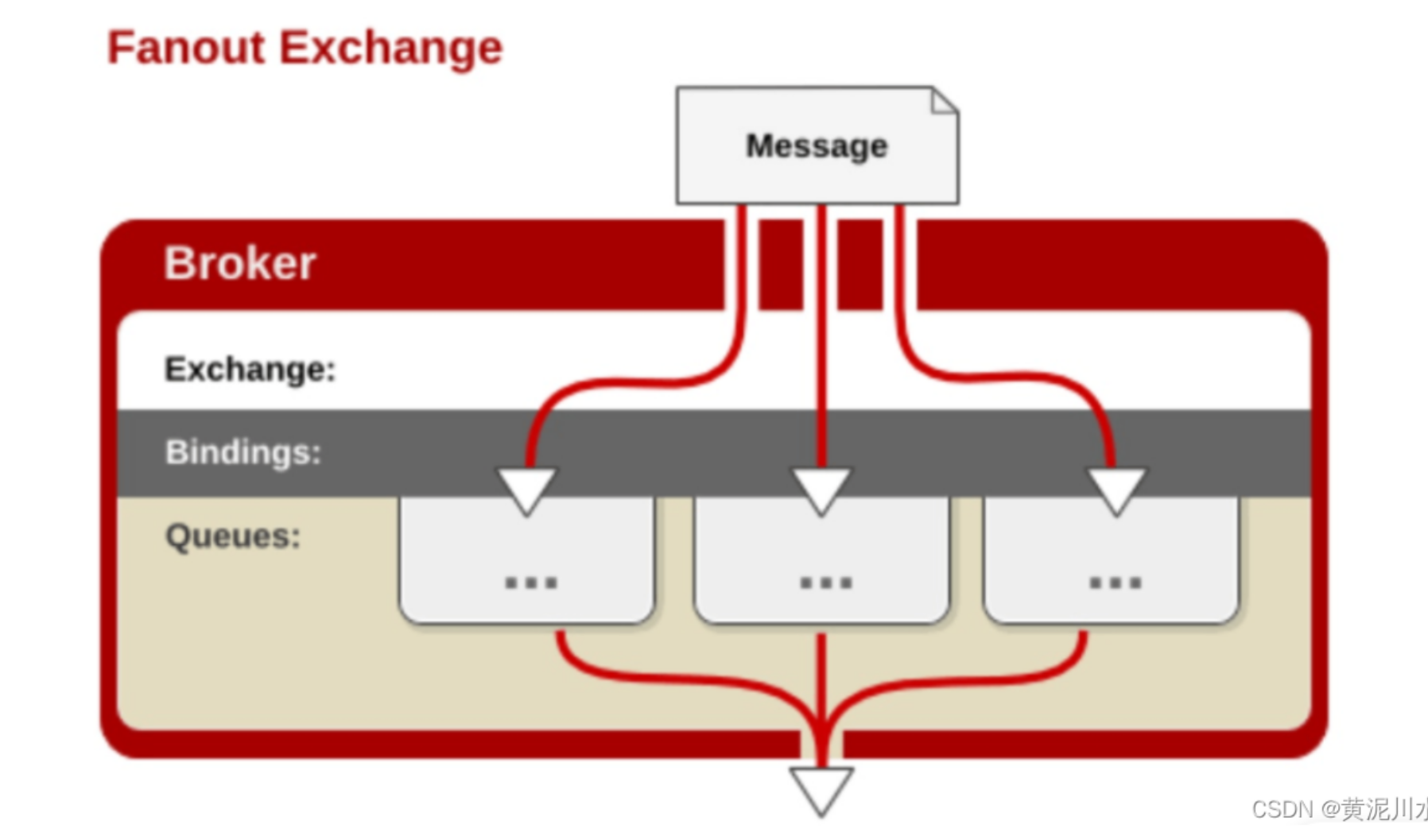
扇出(fanout):
它是将接收到的所有消息广播到它知道的所有队列中
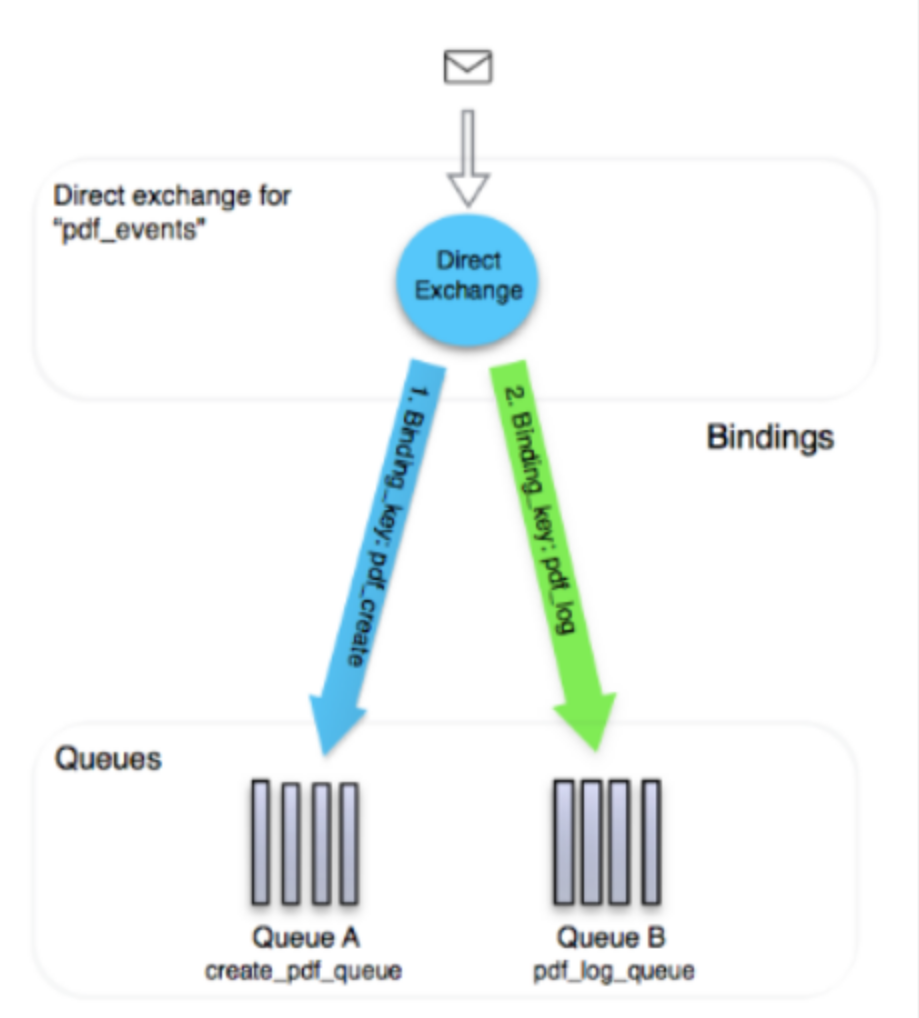
直接(direct):
exchange在和queue进行binding时会设置routingkey
channel.QueueBind(queue: "create_pdf_queue",
exchange: "pdf_events",
routingKey: "pdf_create",
arguments: null);
将消息发送到exchange时会设置对应的routingkey
channel.BasicPublish(exchange: "pdf_events",
routingKey: "pdf_create",
basicProperties: properties,
body: body);
在direct类型的exchange中,只有这两个routingkey完全相同,exchange才会选择对应的binging进行消息路由
主题(topic):
此类型exchange和上面的direct类型差不多,但direct类型要求routingkey完全相等,这里的routingkey可以有通配符:'‘,’#‘.
其中’'表示匹配一个单词, '#'则表示匹配没有或者多个单词
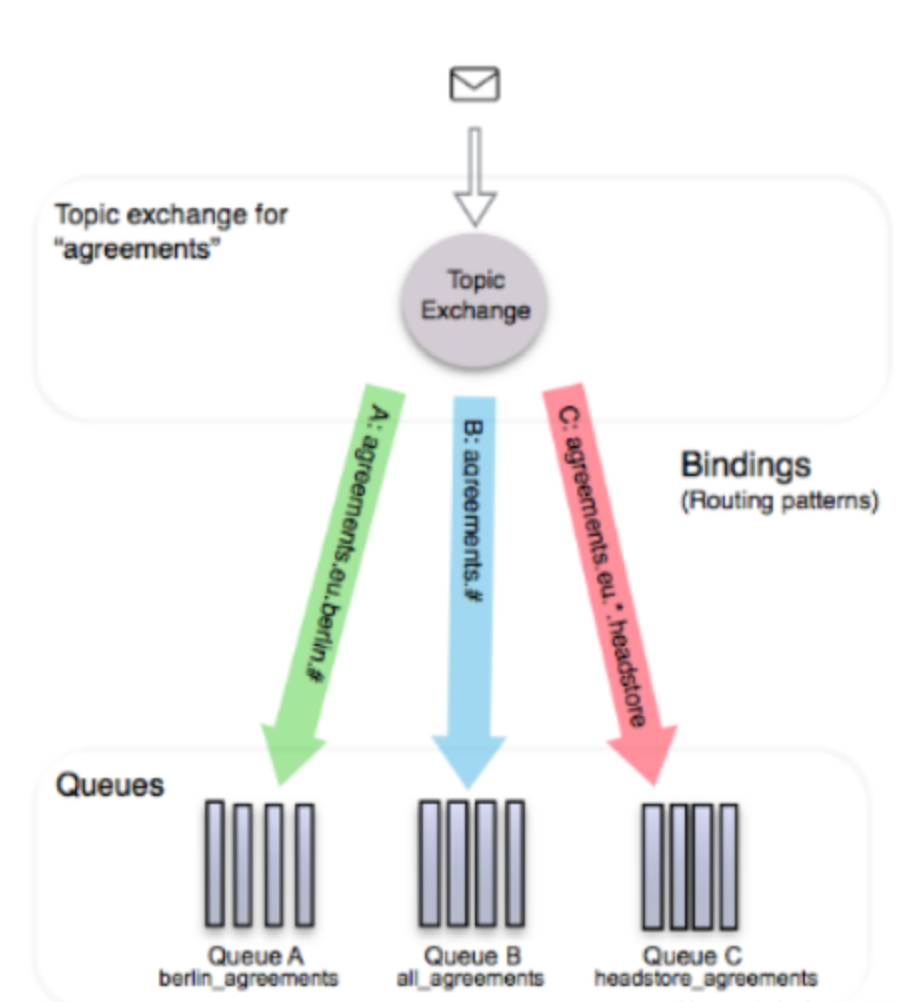
第一个binding
exchange: agreements
queue A: berlin_agreements
binding routingkey: agreements.eu.berlin.#
第二个binding
exchange: agreements
queue B: all_agreements
binding routingkey: agreements.#
第三个binding
exchange: agreements
queue c: headstore_agreements
binding routingkey: agreements.eu.*.headstore
所以如果我们消息的routingkey为agreements.eu.berlin那么符合第一和第二个binding,但最后一个不符合
标题(headers):
不处理路由键。而是根据发送的消息内容中的headers属性进行匹配;在绑定Queue与Exchange时指定一组键值对;当消息发送到RabbitMQ时会取到该消息的headers与Exchange绑定时指定的键值对进行匹配;如果完全匹配则消息会路由到该队列,否则不会路由到该队列
匹配规则x-match有下列两种类型
- x-match = all :表示所有的键值对都匹配才能接受到消息
- x-match = any :表示只要有键值对匹配就能接受到消息
9. Queues 队列
-
name: 队列名称
-
durable: 队列是否持久化;队列默认是存放到内存中的,rabbitmq重启则丢失,保存到Erlang自带的Mnesia数据库中可持久存储
-
exclusive:是否排他的队列
- 当连接关闭时connection.close()该队列是否会自动删除
- 设置队列是否是私有的,如果非排他(false)的,可以使用两个消费者都访问同一个队列,没有任何问题,如果是排他的,会对当前队列加锁,其他通道channel是不能访问的,如果强制访问会报异常
com.rabbitmq.client.ShutdownSignalException: channel error; protocol method: #method<channel.close>(reply-code=405, reply-text=RESOURCE_LOCKED - cannot obtain exclusive access to locked queue ‘queue_name’ in vhost ‘/’, class-id=50, method-id=20 -
autoDelete:是否自动删除,当最后一个消费者断开连接之后队列是否自动被删除;当consumers = 0时队列就会自动删除
-
arguments: 队列中的消息什么时候会自动被删除
- Message TTL(x-message-ttl):设置队列中的所有消息的生存周期;单位毫秒;生存时间到了,消息会被从队里中删除
- Auto Expire(x-expires): 当队列在指定的时间没有被访问(consume, basicGet, queueDeclare…)就会被删除,Features=Exp
- Max Length(x-max-length): 限定队列的消息的最大值长度,超过指定长度将会把最早的几条删除掉,Feature=Lim
- Max Length Bytes(x-max-length-bytes): 限定队列最大占用的空间大小, 一般受限于内存、磁盘的大小, Features=Lim B
- Dead letter exchange(x-dead-letter-exchange): 当队列消息长度大于最大长度、或者过期的等,将从队列中删除的消息推送到指定的交换机中去而不是丢弃掉,Features=DLX
- Dead letter routing key(x-dead-letter-routing-key):将删除的消息推送到指定交换机的指定路由键的队列中去, Feature=DLK
- Maximum priority(x-max-priority):优先级队列,声明队列时先定义最大优先级值(定义最大值一般不要太大),在发布消息的时候指定该消息的优先级, 优先级更高(数值更大的)的消息先被消费
- Lazy mode(x-queue-mode=lazy): Lazy Queues: 先将消息保存到磁盘上,不放在内存中,当消费者开始消费的时候才加载到内存中,Master locator(x-queue-master-locator)
三:RabbitMQ 集群
RabbitMQ一般以集群方式部署,主要提供消息的接受和发送,实现各微服务之间的消息异步。以下将介绍RabbitMQ+HA方式进行部署。
1. 原理介绍
RabbitMQ是依据erlang的分布式特性(RabbitMQ底层是通过Erlang架构来实现的,所以rabbitmqctl会启动Erlang节点,并基于Erlang节点来使用Erlang系统连接RabbitMQ节点,在连接过程中需要正确的Erlang Cookie和节点名称,Erlang节点通过交换Erlang Cookie以获得认证)来实现的,所以部署Rabbitmq分布式集群时要先安装Erlang,并把其中一个服务的cookie复制到另外的节点
RabbitMQ集群中,各个RabbitMQ为对等节点,即每个节点均提供给客户端连接,进行消息的接收和发送。节点分为内存节点和磁盘节点,一般的,均应建立为磁盘节点,为了防止机器重启后的消息消失
RabbitMQ的Cluster集群模式一般分为两种,普通模式和镜像模式。消息队列通过RabbitMQ HA镜像队列进行消息队列实体复制
普通模式下,以两个节点(rabbit01、rabbit02)为例来进行说明。对于Queue来说,消息实体只存在于其中一个节点rabbit01(或者rabbit02),rabbit01和rabbit02两个节点仅有相同的元数据,即队列的结构。当消息进入rabbit01节点的Queue后,consumer从rabbit02节点消费时,RabbitMQ会临时在rabbit01、rabbit02间进行消息传输,把A中的消息实体取出并经过B发送给consumer。所以consumer应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立物理Queue。否则无论consumer连rabbit01或rabbit02,出口总在rabbit01,会产生瓶颈
镜像模式下,将需要消费的队列变为镜像队列,存在于多个节点,这样就可以实现RabbitMQ的HA高可用性。作用就是消息实体会主动在镜像节点之间实现同步,而不是像普通模式那样,在consumer消费数据时临时读取。缺点就是,集群内部的同步通讯会占用大量的网络带宽
2. 集群部署
- 单一模式:即单机情况不做集群,就单独运行一个 rabbitmq 而已
- 普通模式:默认模式,以两个节点(rabbit01、rabbit02)为例来进行说明。对于 Queue 来说,消息实体只存在于其中一个节点 rabbit01(或者 rabbit02),rabbit01 和 rabbit02 两个节点仅有相同的元数据,即队列的结构。当消息进入 rabbit01 节点的 Queue 后,consumer 从 rabbit02 节点消费时,RabbitMQ 会临时在 rabbit01、rabbit02 间进行消息传输,把 A 中的消息实体取出并经过 B 发送给 consumer。所以 consumer 应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立物理 Queue。否则无论 consumer 连 rabbit01 或 rabbit02,出口总在 rabbit01,会产生瓶颈。当 rabbit01 节点故障后,rabbit02 节点无法取到 rabbit01 节点中还未消费的消息实体。如果做了消息持久化,那么得等 rabbit01 节点恢复,然后才可被消费;如果没有持久化的话,就会产生消息丢失的现象
- 镜像模式: 把需要的队列做成镜像队列,存在与多个节点属于 RabbitMQ 的 HA 方案。该模式解决了普通模式中的问题,其实质和普通模式不同之处在于,消息实体会主动在镜像节点间同步,而不是在客户端取数据时临时拉取。该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。所以在对可靠性要求较高的场合中适用
环境准备
3台centos7操作系统,ip分别为:
192.168.159.131
192.168.159.132
192.168.159.133
本地解析(三台)
[root@rabbitmq1/2/3 ~]# vim /etc/hosts
192.168.159.131 rabbitmq1
192.168.159.132 rabbitmq2
192.168.159.133 rabbitmq3
安装erlang、socat和rabbitmq(三台)
[root@rabbitmq1/2/3 ~]# yum -y install erlang
[root@rabbitmq1/2/3 ~]# yum -y install socat
[root@rabbitmq1/2/3 ~]# yum -y install rabbitmq-server
启动服务
每台都操作开启rabbitmq的web访问界面:
[root@rabbitmq1/2/3 ~]# rabbitmq-plugins enable rabbitmq_management
[root@rabbitmq1/2/3 ~]# systemctl start rabbitmq-server.service
[root@rabbitmq1/2/3 ~]# systemctl enable rabbitmq-server
同步erlang cookie
# 选择rabbit1的cookie同步到其他节点
[root@rabbitmq1 ~]# systemctl stop rabbitmq-server
[root@rabbitmq1 ~]# scp /var/lib/rabbitmq/.erlang.cookie root@rabbit2:/var/lib/rabbitmq/
[root@rabbitmq1 ~]# scp /var/lib/rabbitmq/.erlang.cookie root@rabbit3:/var/lib/rabbitmq/
# 所有节点设置cookie权限
[root@rabbitmq1/2/3 ~]# chown rabbitmq:rabbitmq /var/lib/rabbitmq/.erlang.cookie
[root@rabbitmq1/2/3 ~]# chmod 600 /var/lib/rabbitmq/.erlang.cookie
[root@rabbitmq1/2/3 ~]# systemctl restart rabbitmq-server
将节点加入集群
# 在rabbit2执行
[root@rabbitmq2 ~]# rabbitmqctl stop_app
[root@rabbitmq2 ~]# rabbitmqctl reset
[root@rabbitmq2 ~]# rabbitmqctl join_cluster rabbit@rabbitmq1
[root@rabbitmq2 ~]# rabbitmqctl start_app
# 在rabbit3执行
[root@rabbitmq3 ~]# rabbitmqctl stop_app
[root@rabbitmq3 ~]# rabbitmqctl reset
[root@rabbitmq3 ~]# rabbitmqctl join_cluster rabbit@rabbitmq1
[root@rabbitmq3 ~]# rabbitmqctl start_app
验证集群状态
[root@rabbitmq1 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbitmq1 ...
[{nodes,[{disc,[rabbit@rabbitmq1,rabbit@rabbitmq2,rabbit@rabbitmq3]}]},
{running_nodes,[rabbit@rabbitmq3,rabbit@rabbitmq2,rabbit@rabbitmq1]},
{cluster_name,<<"rabbit@rabbitmq1">>},
{partitions,[]}]
...done.
登录rabbitmq web管理控制台
3. 搭建 rabbitmq 的镜像高可用模式集群
这一节要参考的文档是:http://www.rabbitmq.com/ha.html
首先镜像模式要依赖policy模块,这个模块是做什么用的呢?
policy中文来说是政策,策略的意思,那么他就是要设置,那些Exchanges或者queue的数据需要复制,同步,如何复制同步?对就是做这些的。
# 在任意节点执行
[root@rabbitmq1 ~]# rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
参数意思为:
ha-all:为策略名称。
^:为匹配符,只有一个^代表匹配所有,^zlh为匹配名称为zlh的exchanges或者queue。
ha-mode:为匹配类型,他分为3种模式:
- all-所有(所有的 queue),
- exctly-部分(需配置ha-params参数,此参数为int类型比如3,众多集群中的随机3台机器)
- nodes-指定(需配置ha-params参数,此参数为数组类型比如["3rabbit@F","rabbit@G"]这样指定为F与G这2台机器。)。

4. 权限设置(补充)
账号配置
安装启动后其实还不能在其它机器访问,rabbitmq 默认的 guest 账号只能在本地机器访问, 如果想在其它机器访问需配置其它账号
# 可以创建管理员用户,负责整个 MQ 的运维
[root@rabbitmq1 ~]# rabbitmqctl add_user admin admin
Creating user "admin" ...
...done.
# 赋予其 administrator 角色
[root@rabbitmq1 ~]# rabbitmqctl set_user_tags admin administrator
Setting tags for user "admin" to [administrator] ...
...done.
# 赋予其 administrator 角色
[root@rabbitmq1 ~]# rabbitmqctl add_user user_monitoring 123456
Creating user "user_monitoring" ...
...done.
[root@rabbitmq1 ~]# rabbitmqctl set_user_tags user_monitoring monitoring
Setting tags for user "user_monitoring" to [monitoring] ...
...done.
# 创建某个项目的专用用户,只能访问项目自己的 virtual hosts
[root@rabbitmq1 ~]# rabbitmqctl set_user_tags user_monitoring management
Setting tags for user "user_monitoring" to [management] ...
...done.
# 创建和赋角色完成后查看并确认
[root@rabbitmq1 ~]# rabbitmqctl list_users
Listing users ...
admin [administrator]
guest [administrator]
user_monitoring [management]
...done.
设置权限
此处设置权限时注意'.'之间需要有空格 三个'.'分别代表了conf权限,read权限与write权限 例如:当没有给soho设置这三个权限前是没有权限查询队列,在ui界面也看不见
[root@rabbitmq1 ~]# rabbitmqctl set_permissions -p "/" admin ".*" ".*" ".*"
Setting permissions for user "admin" in vhost "/" ...
...done.
查看端口
- 4369 -- erlang发现口
- 5672 --程序连接端口
- 15672 -- 管理界面ui端口
- 25672 -- server间内部通信口
rabbitmq 用户权限 VirtualHost(部署集群过程中不是必须的)
像 mysql 有数据库的概念并且可以指定用户对库和表等操作的权限。那 RabbitMQ 呢?RabbitMQ 也有类似的权限管理。在 RabbitMQ 中可以虚拟消息服务器 VirtualHost,每个 VirtualHost 相当于一个相对独立的 RabbitMQ 服务器,每个 VirtualHost 之间是相互隔离的。exchange、queue、message 不能互通。 在 RabbitMQ 中无法通过 AMQP 创建 VirtualHost,可以通过以下命令来创建
[root@rabbitmq1 ~]# rabbitmqctl add_vhost [vhostname]
通常在权限管理中主要包含三步:
1)新建用户
[root@rabbitmq1 ~]# rabbitmqctl add_user superrd superrd
2)配置权限
set_permissions [-p <vhostpath>] <user> <conf> <write> <read>
[root@rabbitmq1 ~]# rabbitmqctl set_permissions -p / admin '.*' '.*' '.*'
其中,.* 的位置分别用正则表达式来匹配特定的资源,如:
'^(amq.gen.*|amq.default)$'
可以匹配 server 生成的和默认的 exchange,’^$’不匹配任何资源
- exchange 和 queue 的 declare 与 delete 分别需要 exchange 和 queue 上的配置权限
- exchange 的 bind 与 unbind 需要 exchange 的读写权限
- queue 的 bind 与 unbind 需要 queue 写权限 exchange 的读权限 发消息 (publish) 需 exchange 的写权限
- 获取或清除 (get、consume、purge) 消息需 queue 的读权限
示例:我们赋予 superrd 在“/”下面的全部资源的配置和读写权限。
[root@rabbitmq1 ~]# rabbitmqctl set_permissions -p / superrd ".*" ".*" ".*"
注意:”/”代表 virtual host 为“/”这个“/”和 linux 里的根目录是有区别的并不是 virtual host 为“/”可以访问所以的 virtual host,把这个“/”理解成字符串就行。
需要注意的是 RabbitMQ 会缓存每个 connection 或 channel 的权限验证结果、因此权限发生变化后需要重连才能生效。
3)查看权限
[root@rabbitmq1 ~]# rabbitmqctl list_user_permissions admin
[root@rabbitmq1 ~]# rabbitmqctl list_permissions -p /
4)配置角色
[root@rabbitmq1 ~]# rabbitmqctl set_user_tags [user] [role]
RabbitMQ 中的角色分为如下五类:none、management、policymaker、monitoring、administrator